













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
BIOGRAPHY
I am a Senior Manager working on AI/ML Research at NVIDIA in Zurich, Switzerland. I lead the FrontierEval - Research group in the Deep Learning Algorithms larger team, focused on LLM Capability Measurement and Failure Analysis. Our group's mission is to build methods and tools that help closing the model development loop by providing data-driven insights and automated evaluations. These insights impact and inform the upstream stack of data quality enhancements, RL environments, and model training for the Nemotron family of models and broader AI efforts at NVIDIA.
Our group is hiring for full-time positions! on research and development roles. Apply and reach out if you are interested and passionate about building the future of open-source first AI!
Prior to joining NVIDIA, I was a Senior Principal Research Manager at Microsoft Research (2017-2025) where I spent eight years working on AI/ML Research on Responsible AI and Human-AI Collaboration. During this time, I led the research efforts behind Eureka ML Insights and the Responsible AI Dashboard & Toolbox for DL model evaluation and debugging. During my time at Microsoft Research, I was also lucky to collaborate with many talented and interdisciplinary researchers studying the principles of joint Human-AI Decision-Making and Interaction.
I completed my PhD degree at ETH Zurich (Switzerland) in the Systems Group in 2016. My doctoral thesis focuses on the impact of crowdsourced data quality on the performance of machine learning models.
I completed my master studies in computer science in a double-degree MSc program at RWTH University of Aachen (Germany) and University of Trento (Italy) as an Erasmus Mundus scholar. My Computer Science journey started at University of Tirana (Albania), from which I hold a Diploma in Informatics and where I spent three years as a Lecturer in Computer Science.
About me

AI/ML researcher working on AI Capability Evaluation & Analysis.
Albania
Zurich
Keynote: The Unbearable Lightness of (Agentic) Evaluations
Talk: The Science and Practice of Open and Scalable LLM Evaluations
April 2026 - I will attend ICLR 2026 in Rio de Janeiro. Reach out if you want to meet up! Together with current and past collaborators, we will be presenting our latest work on:
- Detecting Data Contamination in LLMs via In-Context Learning
- Tracing the Traces: Latent Temporal Signals for Efficient and Accurate Reasoning
- Just Do It!? Computer-Use Agents Exhibit Blind Goal-Directedness
March 2026 - NVIDIA released Nemotron 3 Super. This release acknowledges the importance of enabling the model developer community with end-to-end recipes for everything: data, training, evaluation, and support software. Our group conducted the open-source evaluations for the model, find the open eval recipes in our collection inside Nemo Evaluator SDK.
December 2025 - FrontierEval attended NeurIPS 2025. Michal Zawalski and Meriem Boubdir presented CoDeC, a model-agnostic method for detecting training data contamination, at the LLM Evaluation workshop. The team also gave a live demo of our recently released open-source tool for LLM accuracy evaluation: Nemo Evaluator SDK.
December 2025 - NVIDIA released Nemotron 3 Nano, a hybrid Mamba-Transformer mixture-of-experts model for agentic reasoning. We used Nemo Evaluator SDK to open source the evaluation stack and recipes for the model.
September 2025 - The FrontierEval team released Nemo Evaluator SDK. It is an open-source library for scalable, reproducible evaluation of AI models and benchmarks. Give it a try!
August 2025 - After eight wonderful years at Microsoft Research, I joined NVIDIA to lead the research efforts in the FrontierEval, Deep Learning Algorithms group, focused on LLM Capability Measurement and Analysis. I also (once again) moved continents and am back in Zurich, Switzerland.
DEBUGGING AND FAILURE ANALYSIS FOR AI
How can we better understand failures of an AI system?
⥥ Measurement: “If you can’t measure it you can’t improve it.” - William Thompson
⥥ Insights: “Any fool can know. The point is to understand.” - Albert Einstein
⥥ Improvements: “Insight without action is worthless. Understanding must lead to transformation.” - Marie Forleo
As expectations for AI capabilities and reliability grow, so does the need for better understanding of AI failures and how to improve them. This is a key area of research for the FrontierEval team, where we are developing new methods that analyze granular (disaggregated) outcomes of benchmark evaluations and real-world interactions of users with AI systems. This analysis helps us gain grounded insights into the capabilities and limitations of AI systems, and how to improve them. We also work on better understanding and measuring the quality of training data and its impact on model accuracy, generalization, robustness, and token/tool usage efficiency.
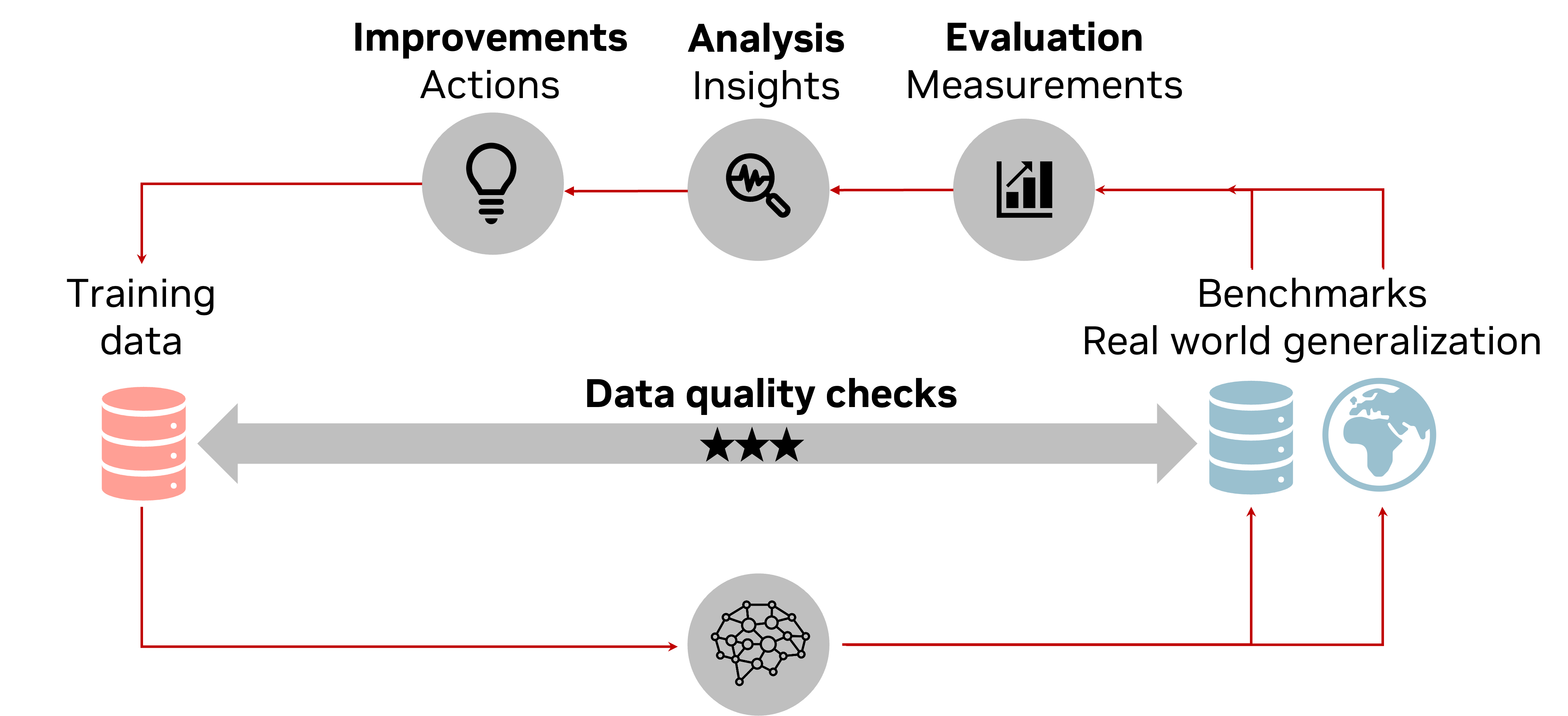
Insights-driven AI development lifecycle
Examples of our recent research work on debugging and failure analysis for AI:
- CoDeC: A model-agnostic method for stuyding and detecting data contamination in LLMs via in-context learning. The work observes that LLM confidence is not improved by in-context examples and might even drop when the model has seen a benchmark in training. Work led by Michal Zawalski (NVIDIA) and Meriem Boubdir (NVIDIA).
- Latent Trajectory Analysis: An accuracy prediction method that uses characterizations of the temporal evolution of a model’s internal representations during the generation of intermediate reasoning tokens. The method can be used for answer selection and cost reduction in long reasoning tasks. Work led by Martina G Vilas (Goethe University).
- Blind-Act: A study and benchmark for measuring the goal-directedness tendency of computer-use agents to take spurrious shortcuts, while pursuing complex goals. The workfinds that current agents are not (yet) able to reason about task feasibility or action safety as they first and foremost aim to complete their main goal. Work led by Erfan Shayegani (University of California, Riverside).
LLM EVALUATION WITH NEMO EVALUATOR SDK
Open-source library for scalable, reproducible evaluation of AI models and benchmarks.
LLM Capability evaluation is a complex and challenging task. Many challenges arise from the the diversity of the tasks and datasets and the lack of consistency and transparency in the evaluation process. Even for a single simple benchmark, where the evaluation is considered to be straightforward, there are exist too many flavors and variations of the evaluation process. In fact, such variations can be so subtle that the quest to reproducing a single evaluation can be daunting and costly.
Nemo Evaluator SDK is a open-source library for scalable, reproducible evaluation of AI models and benchmarks. It provides a comprehensive suite of tools and frameworks for evaluating the performance of AI models on a wide range of tasks and datasets. The main philosophy behind the project is that all model evaluations must be consistent across models, reproducible, and transparent. Following this philosophy, we use the SDK to evaluate the capabilities of the Nemotron family of models and other models in the open-source community by providing open-source evaluation recipes, a practice that we hope will become the standard for the industry.
From a research perspective, our team also works on developing new measurements methods and benchmarks for capabilities and aspects of AI behaviorthat are not yet well-understood and that matter for real-world applications. This includes studying data contamination and its impact to generalization and robustness of models, agentic reasoning, and hallucinations.
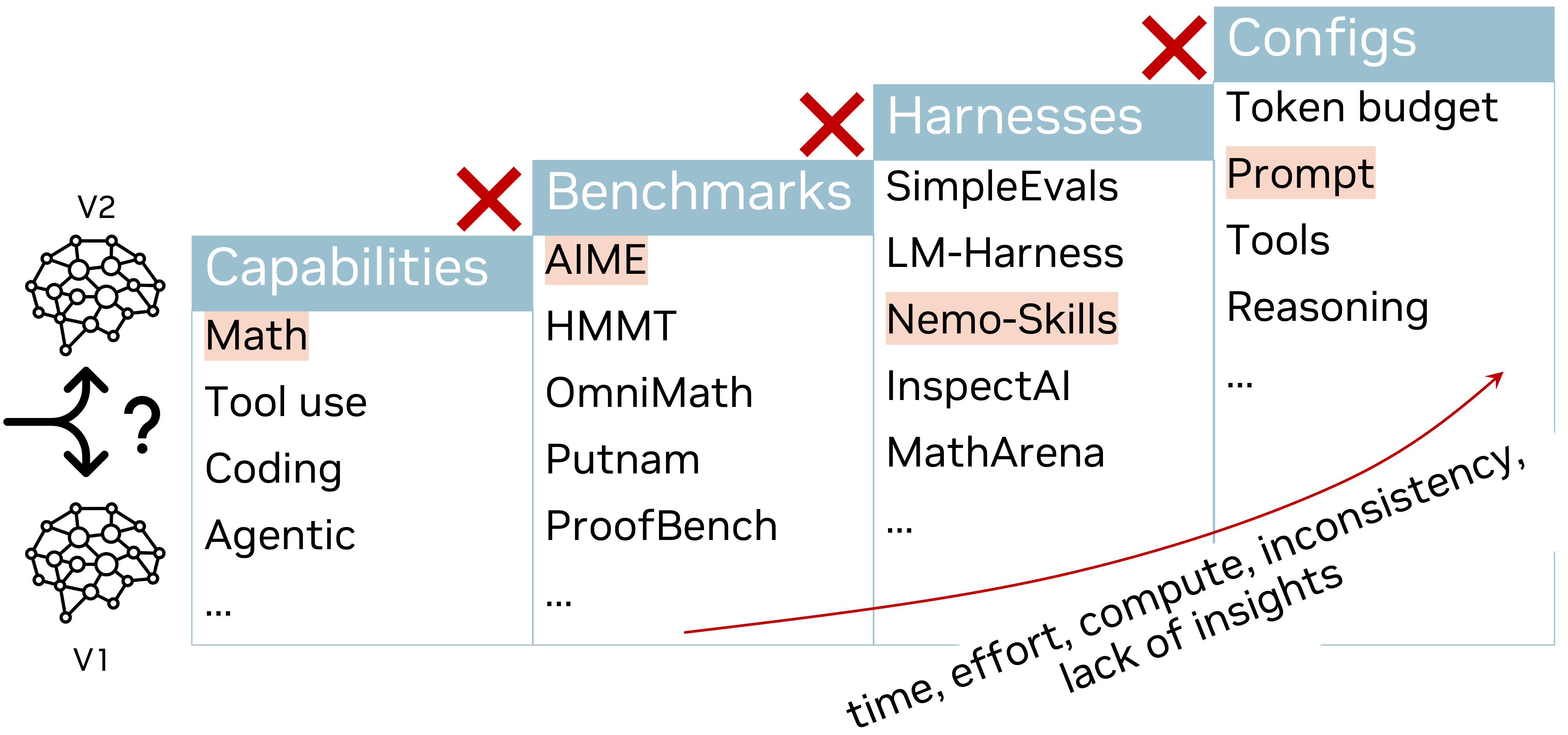
LLM Evaluation Challenges
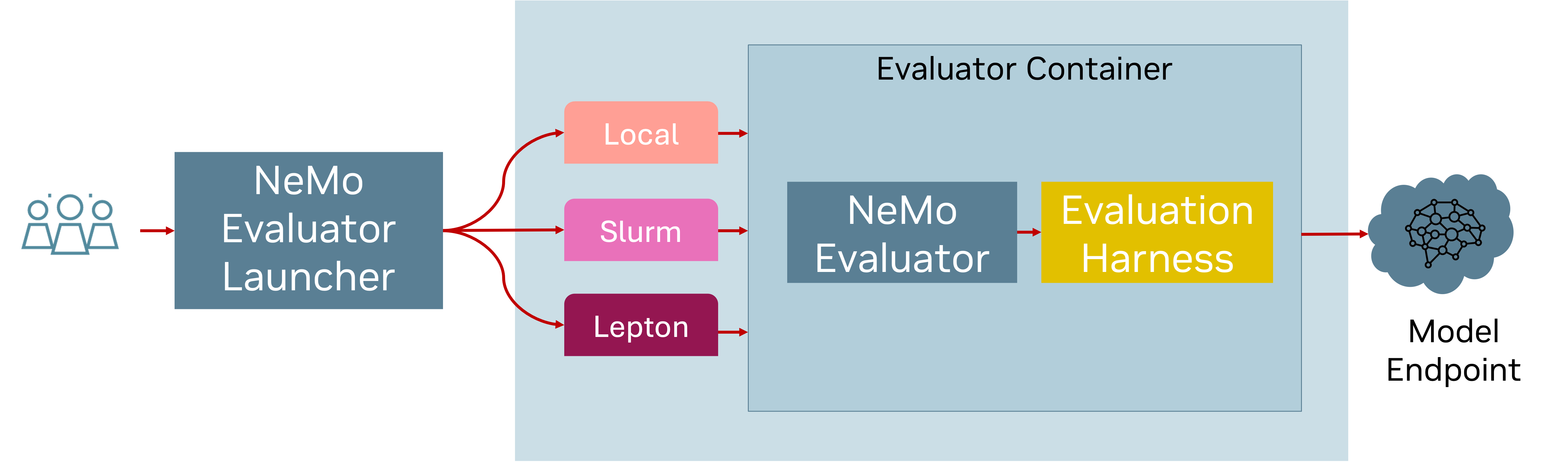
Nemo Evaluator SDK
Tracing the Traces: Latent Temporal Signals for Efficient and Accurate Reasoning. Martina G Vilas, Safoora Yousefi, Besmira Nushi, Eric Horvitz, Vidhisha Balachandran; ICLR 2026. pdf
Just Do It!? Computer-Use Agents Exhibit Blind Goal-Directedness. Erfan Shayegani, Keegan Hines, Yue Dong, Nael Abu-Ghazaleh, Roman Lutz, Spencer Whitehead, Vidhisha Balachandran, Besmira Nushi, Vibhav Vineet; ICLR 2026. pdf
Detecting Data Contamination in LLMs via In-Context Learning. Michal Zawalski, Meriem Boubdir, Klaudia Bałazy, Besmira Nushi, Pablo Ribalta; ICLR 2026. pdf
NVIDIA Nemotron 3: Efficient and Open Intelligence. Aaron Blakeman, Aaron Grattafiori, Aarti Basant, Abhibha Gupta, Abhinav Khattar, Adi Renduchintala, et al.; arXiv:2512.20848, NVIDIA 2025. pdf
Inference-time scaling for complex tasks: Where we stand and what lies ahead. Vidhisha Balachandran, Jingya Chen, Lingjiao Chen, Shivam Garg, Neel Joshi, Yash Lara, John Langford, Besmira Nushi, Vibhav Vineet, Yue Wu, Safoora Yousefi; arXiv:2504.00294, 2025. pdf
Eureka: Evaluating and understanding large foundation models. Vidhisha Balachandran, Jingya Chen, Neel Joshi, Besmira Nushi, Hamid Palangi, Eduardo Salinas, Vibhav Vineet, James Woffinden-Luey, Safoora Yousefi; arXiv:2409.10566, 2024. pdf
Attention satisfies: A constraint-satisfaction lens on factual errors of language models. Mert Yuksekgonul, Varun Chandrasekaran, Erik Jones, Suriya Gunasekar, Ranjita Naik, Hamid Palangi, Ece Kamar, Besmira Nushi; ICLR 2024. pdf
Social Biases through the Text-to-Image Generation Lens. Ranjita Naik, Besmira Nushi; AAAI/ACM Conference on AI, Ethics, and Society (AIES), 2023. pdf
Updates in Human-AI Teams: Understanding and Addressing the Performance/Compatibility Tradeoff. Gagan Bansal, Besmira Nushi, Ece Kamar, Daniel S Weld, Walter Lasecki**, Eric Horvitz; AAAI 2019. pdf
Towards Accountable AI: Hybrid Human-Machine Analyses for Characterizing System Failure. Besmira Nushi, Ece Kamar, Eric Horvitz; HCOMP 2018. pdf
LIST OF PUBLICATIONS AND TECHNICAL REPORTS
Tracing the Traces: Latent Temporal Signals for Efficient and Accurate Reasoning. Martina G Vilas, Safoora Yousefi, Besmira Nushi, Eric Horvitz, Vidhisha Balachandran; ICLR 2026. pdf
Just Do It!? Computer-Use Agents Exhibit Blind Goal-Directedness.Erfan Shayegani, Keegan Hines, Yue Dong, Nael Abu-Ghazaleh, Roman Lutz, Spencer Whitehead, Vidhisha Balachandran, Besmira Nushi, Vibhav Vineet; ICLR 2026. pdf
Detecting Data Contamination in LLMs via In-Context Learning. Michal Zawalski, Meriem Boubdir, Klaudia Bałazy, Besmira Nushi, Pablo Ribalta; ICLR 2026. pdf
Attention speaks volumes: Localizing and mitigating bias in language models. Rishabh Adiga, Besmira Nushi, Varun Chandrasekaran; ACL 2025. pdf
Inference-time scaling for complex tasks: Where we stand and what lies ahead. Vidhisha Balachandran, Jingya Chen, Lingjiao Chen, Shivam Garg, Neel Joshi, Yash Lara, John Langford, Besmira Nushi, Vibhav Vineet, Yue Wu, Safoora Yousefi; arXiv:2504.00294, 2025. pdf
LogiPlan: A Structured Benchmark for Logical Planning and Relational Reasoning in LLMs. Yanan Cai, Ahmed Salem, Besmira Nushi, Mark Russinovich; arXiv:2506.10527, 2025. pdf
MM-Gen: Principled and Generalizable Data Curation for Enhancing Task Performance in VLMs. Siddharth Joshi, Besmira Nushi, Vidhisha Balachandran, Varun Chandrasekaran, Vibhav Vineet, Neel Joshi, Baharan Mirzasoleiman; Journal of Data-centric Machine Learning Research, 2025. pdf
NVIDIA Nemotron 3: Efficient and Open Intelligence. Aaron Blakeman, Aaron Grattafiori, Aarti Basant, Abhibha Gupta, Abhinav Khattar, Adi Renduchintala, et al.; arXiv:2512.20848, NVIDIA 2025. pdf
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning. Aaron Blakeman, Aaron Grattafiori, Aarti Basant, Abhibha Gupta, Abhinav Khattar, Adi Renduchintala, et al.; arXiv:2512.20848, NVIDIA 2025. pdf
Phi-4-reasoning technical report. Marah Abdin, Sahaj Agarwal, Ahmed Awadallah, Vidhisha Balachandran, Harkirat Behl, Lingjiao Chen, Gustavo de Rosa, Suriya Gunasekar, Mojan Javaheripi, Neel Joshi, Piero Kauffmann, Yash Lara, Caio César Teodoro Mendes, Arindam Mitra, Besmira Nushi, Dimitris Papailiopoulos, Olli Saarikivi, Shital Shah, Vaishnavi Shrivastava, Vibhav Vineet, Yue Wu, Safoora Yousefi, Guoqing Zheng; arXiv:2504.21318, Microsoft Research 2025. pdf
The Singapore consensus on global AI safety research priorities. Yoshua Bengio, Tegan Maharaj, Luke Ong, Stuart Russell, Dawn Song, Max Tegmark, Lan Xue, Ya-Qin Zhang, Stephen Casper, Wan Sie Lee, Sören Mindermann, Vanessa Wilfred, Vidhisha Balachandran, et al.; arXiv:2506.20702, 2025. pdf
BenchAgents: Multi-Agent Systems for Structured Benchmark Creation. Natasha Butt, Varun Chandrasekaran, Neel Joshi, Besmira Nushi, Vidhisha Balachandran; arXiv:2410.22584, 2024. pdf
Elephants never forget: Memorization and learning of tabular data in large language models. Sebastian Bordt, Harsha Nori, Vanessa Rodrigues, Besmira Nushi, Rich Caruana; COLM 2024. pdf
Eureka: Evaluating and understanding large foundation models. Vidhisha Balachandran, Jingya Chen, Neel Joshi, Besmira Nushi, Hamid Palangi, Eduardo Salinas, Vibhav Vineet, James Woffinden-Luey, Safoora Yousefi; arXiv:2409.10566, 2024. pdf
Improving instruction-following in language models through activation steering. Alessandro Stolfo, Vidhisha Balachandran, Safoora Yousefi, Eric Horvitz, Besmira Nushi; ICLR 2025. pdf
Introducing v0.5 of the AI safety benchmark from MLCommons. Bertie Vidgen, Adarsh Agrawal, Ahmed M Ahmed, Victor Akinwande, Namir Al-Nuaimi, Najla Alfaraj, Elie Alhajjar,, et al.; arXiv:2404.12241, MLCommons 2024. pdf
Understanding information storage and transfer in multi-modal large language models. Samyadeep Basu, Martin Grayson, Cecily Morrison, Besmira Nushi, Soheil Feizi, Daniela Massiceti; NeurIPS 2024. pdf
Unearthing skill-level insights for understanding trade-offs of foundation models. Mazda Moayeri, Vidhisha Balachandran, Varun Chandrasekaran, Safoora Yousefi, Thomas Fel, Soheil Feizi, Besmira Nushi, Neel Joshi, Vibhav Vineet; ICLR 2025. pdf
Kitab: Evaluating llms on constraint satisfaction for information retrieval. Marah I Abdin, Suriya Gunasekar, Varun Chandrasekaran, Jerry Li, Mert Yuksekgonul, Rahee Ghosh Peshawaria, Ranjita Naik, Besmira Nushi; ICLR 2024. pdf
Attention satisfies: A constraint-satisfaction lens on factual errors of language models. Mert Yuksekgonul, Varun Chandrasekaran, Erik Jones, Suriya Gunasekar, Ranjita Naik, Hamid Palangi, Ece Kamar, Besmira Nushi; ICLR 2024. pdf
Advancing human-AI complementarity: The impact of user expertise and algorithmic tuning on joint decision making. Kori Inkpen, Shreya Chappidi, Keri Mallari, Besmira Nushi, Divya Ramesh, Pietro Michelucci, et al.; ACM Transactions on Computer-Human Interaction 30 (5) 2023. pdf
Diversity of thought improves reasoning abilities of llms. Ranjita Naik, Varun Chandrasekaran, Mert Yuksekgonul, Hamid Palangi, Besmira Nushi; arXiv:2310.07088, 2023. pdf
Mitigating Spurious Correlations in Multi-modal Models during Fine-tuning. Yu Yang, Besmira Nushi, Hamid Palangi, Baharan Mirzasoleiman; ICML 2023. pdf
Social Biases through the Text-to-Image Generation Lens. Ranjita Naik, Besmira Nushi; AAAI/ACM Conference on AI, Ethics, and Society (AIES), 2023. pdf
Benchmarking spatial relationships in text-to-image generation. Tejas Gokhale, Hamid Palangi, Besmira Nushi, Vibhav Vineet, Eric Horvitz, Ece Kamar, Chitta Baral, Yezhou Yang; arXiv:2212.10015, 2022 pdf
Who goes first? Influences of human-AI workflow on decision making in clinical imaging. Riccardo Fogliato, Shreya Chappidi, Matthew Lungren, Paul Fisher, Diane Wilson, Michael Fitzke, Mark Parkinson, Eric Horvitz, Kori Inkpen, Besmira Nushi; FAccT 2022. pdf
Investigations of Performance and Bias in Human-AI Teamwork in Hiring. Andi Peng, Besmira Nushi, Emre Kıcıman, Kori Inkpen, Ece Kamar; AAAI 2022. pdf
HINT: Integration Testing for AI-based features with Humans in the Loop. Quanze Chen, Tobias Schnabel, Besmira Nushi, Saleema Amershi; IUI 2022. pdf
Understanding Failures of Deep Networks via Robust Feature Extraction. Sahil Singla, Besmira Nushi, Shital Shah, Ece Kamar, Eric Horvitz; CVPR 2021. pdf
Does the Whole Exceed its Parts? The Effect of AI Explanations on Complementary Team Performance. Gagan Bansal, Tongshuang Wu, Joyce Zhou, Raymond Fok, Besmira Nushi, Ece Kamar, Marco Tulio Ribeiro, Daniel S. Weld; CHI 2021. pdf
Is the Most Accurate AI the Best Teammate? Optimizing AI for Teamwork. Gagan Bansal, Besmira Nushi, Ece Kamar, Eric Horvitz, Dan Weld; AAAI 2021. pdf
An Empirical Analysis of Backward Compatibility in Machine Learning Systems. Megha Srivastava, Besmira Nushi, Ece Kamar, Shital Shah, Eric Horvitz; KDD 2020. pdf
SQuINTing at VQA Models: Interrogating VQA Models with Sub-Questions. Ramprasaath R. Selvaraju, Purva Tendulkar, Devi Parikh, Eric Horvitz, Marco Ribeiro, Besmira Nushi, Ece Kamar; CVPR 2020. pdf
Characterizing Search-Engine Traffic toInternet Research Agency Web Properties. Alexander Spangher, Gireeja Ranade, Besmira Nushi, Adam Fourney, Eric Horvitz; WebConf 2020. pdf
Metareasoning in Modular Software Systems: On-the-Fly Configuration using Reinforcement Learning with Rich Contextual Representations. Aditya Modi, Debadeepta Dey, Alekh Agarwal, Adith Swaminathan, Besmira Nushi, Sean Andrist, Eric Horvitz; AAAI 2020. pdf
Beyond Accuracy: The Role of Mental Models in Human-AI Team Performance. Gagan Bansal, Besmira Nushi, Ece Kamar, Daniel S Weld, Walter Lasecki**, Eric Horvitz; HCOMP 2019. pdf
**Statement about author's misconduct
What You See Is What You Get? The Impact of Representation Criteria on Human Bias in Hiring. Andi Peng, Besmira Nushi, Emre Kiciman, Kori Inkpen, Siddharth Suri, Ece Kamar; HCOMP 2019. pdf
Software Engineering for Machine Learning: A Case Study. Saleema Amershi, Andrew Begel, Christian Bird, Rob DeLine, Harald Gall, Ece Kamar, Nachiappan Nagappan, Besmira Nushi, Thomas Zimmermann; ICSE 2019 . pdf
Guidelines for Human-AI Interaction. Saleema Amershi, Dan Weld, Mihaela Vorvoreanu, Adam Fourney, Besmira Nushi, Penny Collisson, Jina Suh, Shamsi Iqbal, Paul Bennett, Kori Inkpen, Jaime Teevan, Ruth Kikin-Gil, Eric Horvitz; CHI 2019. pdf
Updates in Human-AI Teams: Understanding and Addressing the Performance/Compatibility Tradeoff. Gagan Bansal, Besmira Nushi, Ece Kamar, Daniel S Weld, Walter Lasecki**, Eric Horvitz; AAAI 2019. pdf
**Statement about author's misconduct
Overcoming Blind Spots in the RealWorld: Leveraging Complementary Abilities for Joint Execution. Ramya Ramakrishnan, Ece Kamar, Besmira Nushi, Debadeepta Dey, Julie Shah, Eric Horvitz; AAAI 2019. pdf
Towards Accountable AI: Hybrid Human-Machine Analyses for Characterizing System Failure. Besmira Nushi, Ece Kamar, Eric Horvitz; HCOMP 2018. pdf
Analysis of Strategy and Spread of Russia-sponsored Content in the US in 2017. Alexander Spangher, Gireeja Ranade, Besmira Nushi, Adam Fourney, Eric Horvitz; arXiv 2018. pdf
On Human Intellect and Machine Failures: Troubleshooting Integrative Machine Learning Systems. Besmira Nushi, Ece Kamar, Eric Horvitz, Donald Kossmann; AAAI 2017. pdf
Quality Control and Optimization for Hybrid Crowd-Machine Learning Systems. Besmira Nushi; ETH PhD Thesis 2016. pdf
Learning and Feature Selection under Budget Constraints in Crowdsourcing. Besmira Nushi, Adish Singla, Andreas Krause, Donald Kossmann; HCOMP 2016. pdf
Fault-Tolerant Entity Resolution with the Crowd. Anja Gruenheid, Besmira Nushi, Tim Kraska, Wolfgang Gatterbauer, Donald Kossmann; arXiv 2016. full technical report
Crowd Access Path Optimization: Diversity Matters. Besmira Nushi, Adish Singla, Anja Gruenheid, Erfan Zamanian, Andreas Krause, Donald Kossmann; HCOMP 2015. pdf
CrowdSTAR: A Social Task Routing Framework for Online Communities. Besmira Nushi, Omar Alonso, Martin Hentschel, and Vasileios Kandylas; ICWE 2015. pdf full technical report
When is A = B? Anja Gruenheid, Donald Kossmann, Besmira Nushi, Yuri Gurevich; EATCS Bulletin 111 (2013) pdf
Uncertain time-series similarity: Return to the basics. Michele Dallachiesa, Besmira Nushi, Katsiaryna Mirylenka, and Themis Palpanas; Proceedings of the VLDB Endowment 5, no. 11 (2012): 1662-1673. pdf
Similarity matching for uncertain time series: analytical and experimental comparison. Michele Dallachiesa, Besmira Nushi, Katsiaryna Mirylenka, and Themis Palpanas. Proceedings of the 2nd ACM SIGSPATIAL International Workshop on Querying and Mining Uncertain Spatio-Temporal Data, pp. 8-15. ACM, 2011. pdf